

A key challenge in the metaverse is safeguarding user data from theft or exploitation. Federated learning presents a potential solution to this issue. This approach allows for the training of models on local devices and servers, enabling collaborative learning without compromising user privacy. The trained models are then sent to a central server, where they are aggregated to create an improved global model. This enhanced model is then distributed back to the devices, enhancing their performance while keeping sensitive data secure.
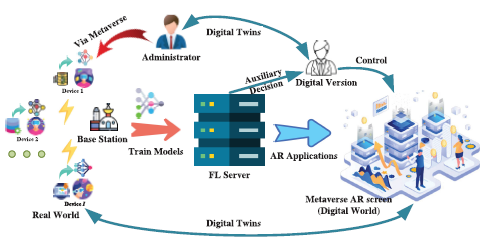
(Reference to the figure above) The illustration demonstrates the federated learning process. A base station receives data from multiple devices. Importantly, only the trained model updates are transmitted, not the raw, personal data residing on the devices. These updates are then combined with the master model at the base station. The resulting, newly trained models are sent to a federated server for further aggregation and refinement. Finally, the updated global model is pushed back to the metaverse and user devices, completing the cycle.
While federated learning offers significant advantages for user privacy in the metaverse, it’s worth noting that it’s a relatively new technology (launched in 2016), and its vulnerabilities warrant careful consideration.
- Costly communication: The distributed nature of federated learning can lead to increased communication costs due to the frequent exchange of model updates between devices and servers.
- System Heterogeneity: The diverse capabilities of devices participating in federated learning can result in performance discrepancies and uneven resource utilization.
- Statistical Heterogeneity: Variations in data distribution and learning patterns across different devices can impact the overall effectiveness of the aggregated model.
- Privacy Concerns: Although federated learning minimizes direct data sharing, it’s not a foolproof solution. There’s a possibility, albeit small, that personal data could be inferred or leaked from local devices.


